webpack 优化指南
6 月 6, 2022 • ☕️☕️☕️ 30 min read
在 webpack4 以后,配置一个简单的打包环境的成本已经变得非常低,并且会根据你选择的 mode 来执行不同的优化,不过所有的优化还是可以手动配置和重写,如果我们不了解其中一些机制的话,很有可能会出现负优化的情况,本文就来记录一下 webpack 都为我们提供了哪些优化打包产物的能力。
1、代码拆分
在这之前,我们假设有一个简单的 webpack 配置和两个 js 文件。
// webpack.config.js
const path = require('path')
module.exports = {
entry: './src/index.js',
mode: 'development',
output: {
filename: 'main.js',
path: path.resolve(__dirname, 'dist'),
},
}
// src/index.js
import _ from 'lodash'
import './module'
console.log(_.join(['Another', 'module', 'loaded!'], ' '))
// src/module.js
import _ from 'lodash'
console.log(_.join(['Another', 'module', 'loaded!'], ' '))
上述的配置会通过 /src/index.js 作为入口,收集所有的依赖并且打包在一个 main.js 的文件中。
但是在实际开发中,我们不可能将所有模块打包在一个文件中,这会导致最后的产物过大。通常我们会代码拆分到不同的 bundle,然后可以按需或者并行加载这些文件,如果使用的合理会极大的减少加载时间。常用的代码分离的方法有两种:
-
多入口:使用 entry 配置手动地分离代码。
-
动态导入:通过模块的内联函数调用来分离代码。
多入口
多入口的模式需要我们自己手动指定哪些模块是要拆分的,然后引入时再手动引入这些拆分好的模块,让我们修改下 webpack 的配置看下如何通过多入口来拆分 bundle (修改后 index.js 中就不需要引用 module.js 了)。
const path = require('path')
module.exports = {
mode: 'development',
entry: {
index: './src/index.js',
another: './src/module.js',
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
},
}
这样我们就可以拆分出两个模块了,不过这种方式存在一些问题:
-
如果多个模块之间有重复的依赖,那这些的依赖会被重复打包到各个 bundle 中
-
这种方法不够灵活,并且不能动态地将核心应用程序逻辑中的代码拆分出来。
第二条不用过多解释,第一条的问题是很严重,如果我两个模块都用到了 lodash,那 lodash 这个依赖会被打包两次,例如下图 index.bundle.js 和 another.bundle.js 的体积都达到了 554kiB。
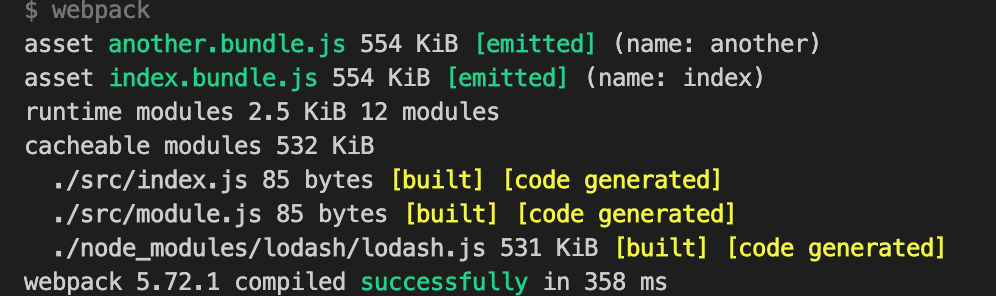
这显然是不能被接受的,我们可以在打包配置中指定哪些是公共依赖来解决这个问题。
const path = require('path')
module.exports = {
mode: 'development',
entry: {
index: {
import: './src/index.js',
// 关键代码
dependOn: 'shared',
},
another: {
import: './src/module.js',
// 关键代码
dependOn: 'shared',
},
// 关键代码
shared: 'lodash',
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
},
}
通过上述配置打包可以看到拆分出了一个 shared 的 bundle,而剩余的两个模块的体积也降回了 1.6k。
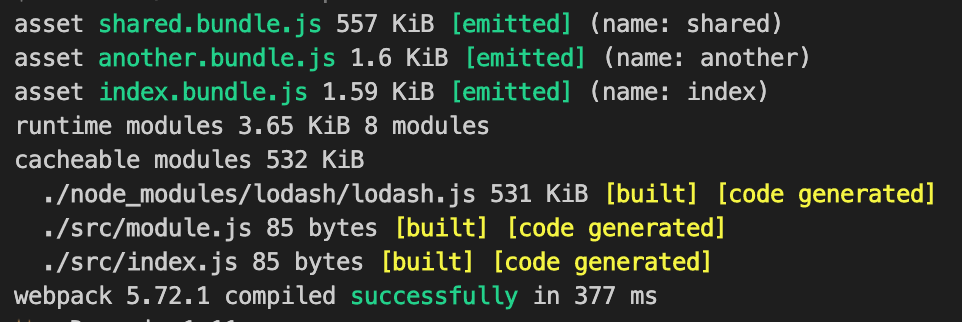
虽然这种方式可以实现代码的拆分,但是需要我们手动去指定提取哪些模块,这显然不是我们期望的效果,那有没有一种方式可以让 webpack 自动提取公共的模块呢?
SplitChunksPlugin 插件可以将公共的依赖模块提取到已有的入口 chunk 中,或者提取到一个新生成的 chunk。
const path = require('path')
module.exports = {
mode: 'development',
entry: {
index: './src/index.js',
another: './src/module.js',
},
output: {
filename: '[name].bundle.js',
path: path.resolve(__dirname, 'dist'),
},
// 关键代码
optimization: {
splitChunks: {
chunks: 'all',
},
},
}
通过上述配置打包我们可以看到,lodash 的依赖被单独抽离成了一个 bundle。
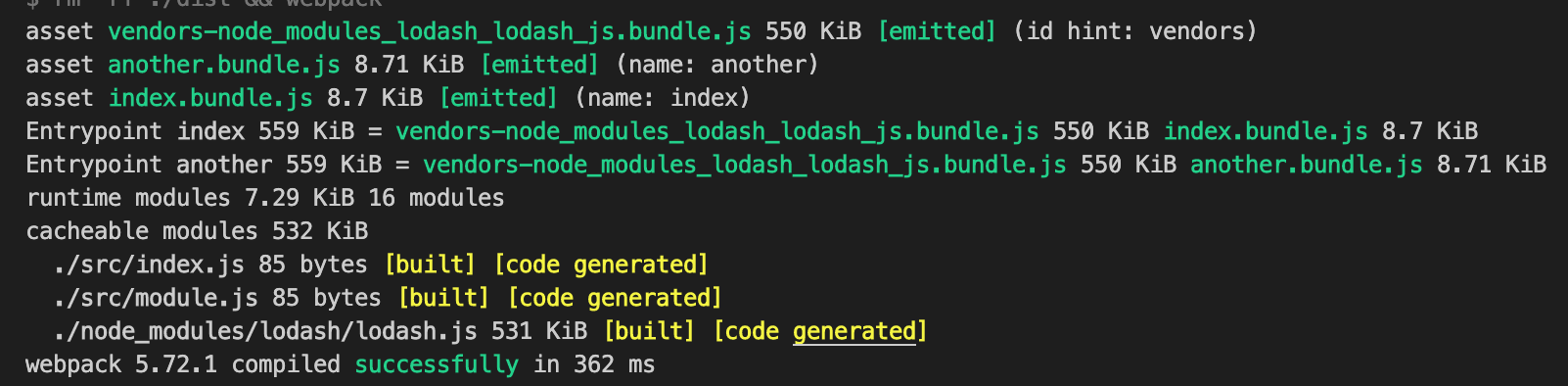
通过这种方式我们就可以不用手动的指定要提取哪些公共依赖了。
代码拆分 - 动态导入
当涉及到动态代码拆分时,webpack 提供了两个类似的技术。第一种,也是推荐选择的方式是,使用符合 ECMAScript 提案 的 import() 语法 来实现动态导入。第二种,则是 webpack 的遗留功能,使用 webpack 特定的 require.ensure,这里我们只关心第一种。
让我们将配置恢复原来的模样。
// webpack.config.js
const path = require('path')
module.exports = {
entry: './src/index.js',
mode: 'development',
output: {
filename: 'main.js',
path: path.resolve(__dirname, 'dist'),
},
}
修改一下 src/index.js 引入其他模块的方式。
import('lodash').then(({ default: _ }) => {
console.log(_.join(['Another', 'module', 'loaded!'], ' '))
})
import('./module')
经过上述修改后打包可以看到,已经拆分出了三个 bundles。
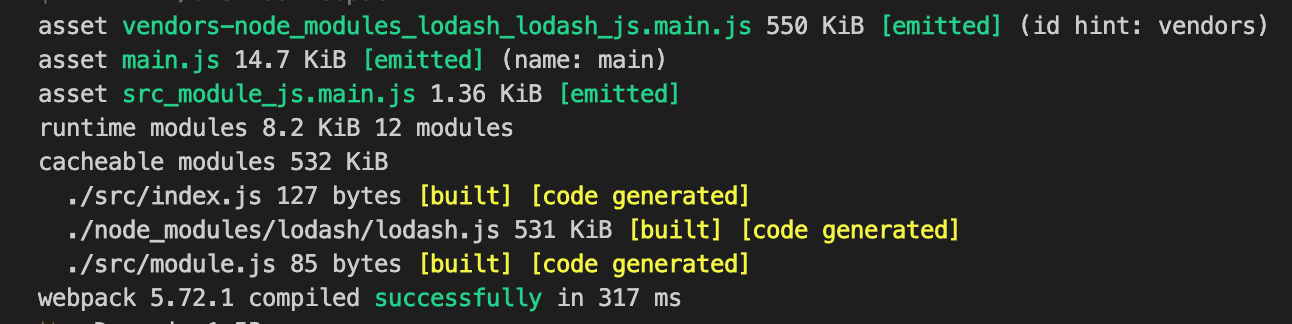
而且与多入口的方式不同,多入口的打包方式需要将拆分后的 js 都引入的 html 中,但是动态引入我们只需要引入 main.js 即可,原因是 main.js 会动态创建两个 script 标签去引入拆分的 bundle。
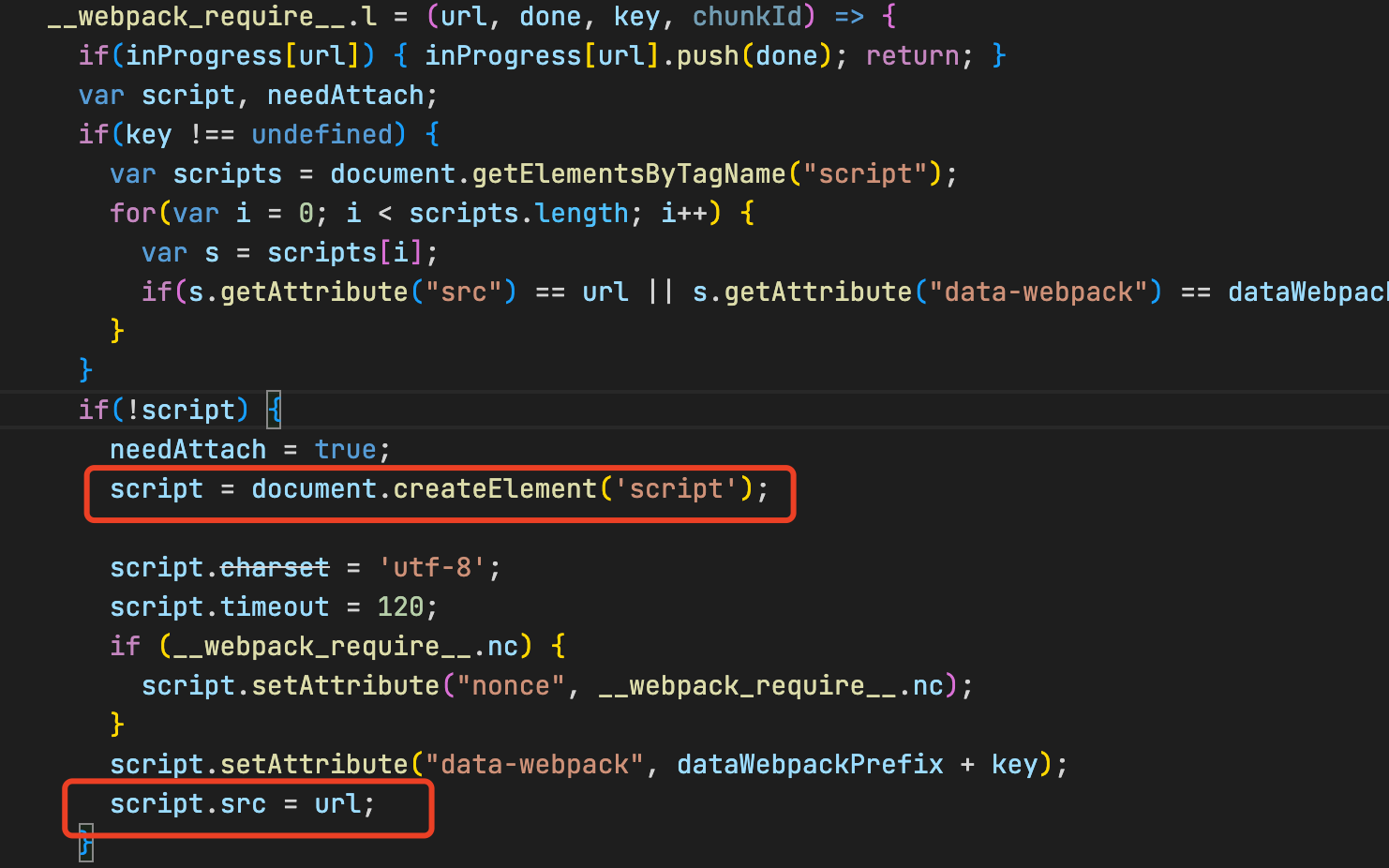
等动态创建的 js 加载完成后会再删除这个 script 标签。
多入口和动态引入都可以帮我们做代码拆分,但他们使用的场景是不同的。多入口往往是用在约定式路由的场景,例如 src 下的某个目录下的所有文件组成这个应用的路由,然后在 webpack 中通过文件读取获取这些文件列表当做打包入口。动态导入通常是用在我们要自己手动控制要拆分哪些模块的场景。
2、Tree Shaking
tree shaking 是一个术语,通常用于描述移除 JavaScript 上下文中的未引用代码(dead-code)。它依赖于 ES2015 模块语法的 静态结构 特性,例如 import 和 export。这个术语和概念实际上是由 ES2015 模块打包工具 rollup 普及起来的。
webpack 的 tree-shaking 和其他的打包工具相比有一个特殊的地方,那就是 sideEffects,在 package.json 中添加这个配置可以指定你当前的模块是否存在副作用。在一个纯粹的 ESM 模块世界中,很容易识别出哪些文件有副作用,然而,我们的项目无法达到这种纯度,所以需要我们去手动指定哪些模块是是否存在副作用。
假设我们有以下配置和文件,webpack config 就是一个最简单的生产环境配置,index.js 引用了 module 里的 random 方法。
// webpack.config.js
const path = require('path')
module.exports = {
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist'),
},
mode: 'production',
}
// src/index.js
import { random } from './module'
const res = random()
console.log('res: ', res)
// src/module.js
export function random() {
return Math.random()
}
export function add(a, b) {
return a + b
}
按照期望我们的打包产物里应该只有 random 方法的调用,让我们看下打包的结果。
;(() => {
'use strict'
const o = Math.random()
console.log('res: ', o)
})()
这个结果完全符合我们的期望,但是如果我们的模块中存在有副作用的代码会有什么影响呢?我们在 module.js 中添加一个全局变量。
// src/module.js
export function random() {
return Math.random()
}
export function add(a, b) {
return a + b
}
// 有副作用的代码
window.test = true
我们再看一下打包后的代码,可以发现 window.test 被打包到了最后的产物中,这是完全合理的,因为通过 ESM 的静态分析是无法判断你是否使用了 test 这个变量,为了保证程序最终的运行不会出现问题,webpack 只能将这段有副作用的代码打包进最终的产物。
;(() => {
'use strict'
window.test = !0
const o = Math.random()
console.log('res: ', o)
})()
sideEffects
如果所有代码都不包含副作用,我们就可以简单地将该属性标记为 false,来告知 webpack 它可以安全地删除未用到的 export。
按照文档中的描述,如果我们在 package.json 中添加 sideEffects 为 false,那这就代表我们的项目中所有的模块都是没有副作用的,在 webpack 打包的时候就会对其进行删除,那我们在原来的示例的基础上添加 sideEffects,看一下最终的打包产物里还会不会有 window.test 这段有副作用的代码。
{
"name": "webpack-demo",
"sideEffects": false,
}
我们发现最终的产物里还是存在 window.test。
;(() => {
'use strict'
window.test = !0
const o = Math.random()
console.log('res: ', o)
})()
是文档里说错了吗?其实是我们理解的有偏差,sideEffects 是可以指定我们项目中所有的模块都是纯净的,但是 webpack 删除有副作用模块的前提是我们没有使用这个模块里的任何方法或者变量。我们在 index.js 里使用到了 module.js 里的 random 方法,所以 webpack 就不能删除 module 这个模块里的副作用代码。
让我们再添加一个 module2.js。
// src/module2.js
export const value = 1
// 有副作用
window.value = 1
然后在 module.js 中引入 value 并且导出,index.js 保持不变,仍然只引用 random 方法。
// src/module.js
import { value } from './module2'
export function random() {
return Math.random()
}
export function add(a, b) {
return a + b
}
export { value }
window.test = true
再让我们看下现在的打包结果,我们发现在 module2.js 中声明的 window.value 没有出现在最终的打包产物里,因为自始至终 module2 除了被 module 导出以外,没有任何地方使用到 module2 里的任何变量或者方法,这时候我们通过 sideEffects 指定所有的模块都是纯净的,webpack 就会直接把 module2 整个模块过滤掉,而不再去解析内部的代码。
;(() => {
'use strict'
window.test = !0
const o = Math.random()
console.log('res: ', o)
})()
如果我们删除 package.json 中的 sideEffects,我们会发现 window.value 出现在了最终的产物里。
{
"name": "webpack-demo",
// "sideEffects": false,
}
;(() => {
'use strict'
;(window.value = 1), (window.test = !0)
const o = Math.random()
console.log('res: ', o)
})()
到这里我们应该可以理解 sideEffects 的作用了,他并不是无脑帮 webpack 删除有副作用的代码,而是在确定了某个模块里没有任何内容被使用的时将这个模块在打包流程中过滤掉,不知道大家有没有发现一个问题,以下引入方式是不是也没使用到 index.css 里的任何方法或者变量?没错,如果 sideEffects 没有将 css 排除在外的话,在打包的时候 index.css 就会被过滤掉,从而导致样式丢失。
import './index.css'
例如 swiper6.x 组件中的 effect-fade 的样式文件,我们就不能直接对其引用,否则就会出现样式丢失的问题。

综上所述,如果我们合理的使用 sideEffects 这个属性,可以使 tree-shaking 的效果更加显著。
Source Mapping
在生产环境,我们的代码往往经过压缩丑化的等一系列操作以后已经不再是人类能够阅读的了,这时候如果出现线上问题,错误日志同样也会变得不可读,为了解决打包后代码可以映射到源码,webpack 提供了 sourceMap 的能力。
我们假设有以下配置和 js 文件。
// webpack.config.js
const path = require('path')
module.exports = {
entry: './src/index.js',
output: {
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist'),
},
mode: 'production',
// 使用生产环境推荐的source-map
devtool: 'source-map',
}
// src/index.js
function random() {
return Math.random()
}
const res = random()
res.map((item) => item + 1)
打包后我们发现在生成了 bundle.js 以外还生成了一个.map 文件,这个.map 文件就是 bundle.js 的 sourceMap 文件。
如何找到对应的 sourceMap?
在最终的产物底部会有一段注释来指定当前 bundle 对应的 sourceMap
Math.random().map((a) => a + 1)
//# sourceMappingURL=bundle.js.map
sourceMap 如何映射源码?
让我们看一下 sourceMap 文件的内容。
{
"version": 3,
"file": "bundle.js",
"mappings": "AACSA,KAAKC,SAGVC,KAAKC,GAASA,EAAO",
"sources": [
"webpack://webpack-demo/./src/index.js"
],
"sourcesContent": [
"function random() {\n return Math.random();\n}\nconst res = random();\nres.map((item) => item + 1);\n"
],
"names": [
"Math",
"random",
"map",
"item"
],
"sourceRoot": ""
}
大部分字段的含义通过内容就很容易推测,唯一有点疑问的字段就是 mapping。这个字段的值是通过 Base64 编码展示的,例如 mappings 的第一个元素 AACSA 表示[0,0,1,9,0],通过这里可以看到转换后的值,每个字母所代表的的含义可以查看这里,简单翻译下可以得知:
-
第一个字母表示在生成后的代码中的列数
-
第二个字母表示对应的 source 列表下标
-
第三个字母表示源码的行数
-
第四个字母表示源码的列数
-
第五个字母表示 names 列表中的下标
这里的每个字母对应的数字是偏移量,并不是实际的值,并且实际数值要多 1。我们看下示例:
- AACSA 表示 [0,0,1,9,0],意思就是:names 列表里的第 0 个字母 Math 在编译后的代码的第 1 列,在源码的第 2 行第 10 列
- KAAKC 表示 [5,0,0,5,1],意思就是:names 列表里的第 1(0 + 1) 个字母 random 在编译后的代码的第 6(1 + 5)列,在源码的第 2(2 + 0) 行第 15(10 + 5) 列
- SAGVC 表示 [9,0,3,-10,1],意思就是:names 列表里的第 2(1 + 1) 个字母 map 在编译后的代码的第 15(6 + 9)列,在源码的第 5(2 + 3) 行第 5(15 - 10) 列
依此类推...
通过这种方式就可以将打包后的代码定位到源码的相应位置,例如这里由于 Math.random 的返回值没有 map 方法导致报错,可以看到错误已经定位到了 index.js:5:5。
